Последние годы наиболее актуальным и современным подходом организации компонентов приложения считается так называемая чистая архитектура. Наверняка вы с ней знакомы, но если есть желание освежить память — рекомендую начать со статьи Общие архитектуры веб-приложений с сайта Microsoft Learn. В этой статье представлена эволюция архитектурных подходов с их достоинствами и недостатками. Далее можно переходить к оригинальной статье Роберта Мартина The Clean Architecture, перевод которой есть на Хабре. Схематически автор выражает идею вот так:
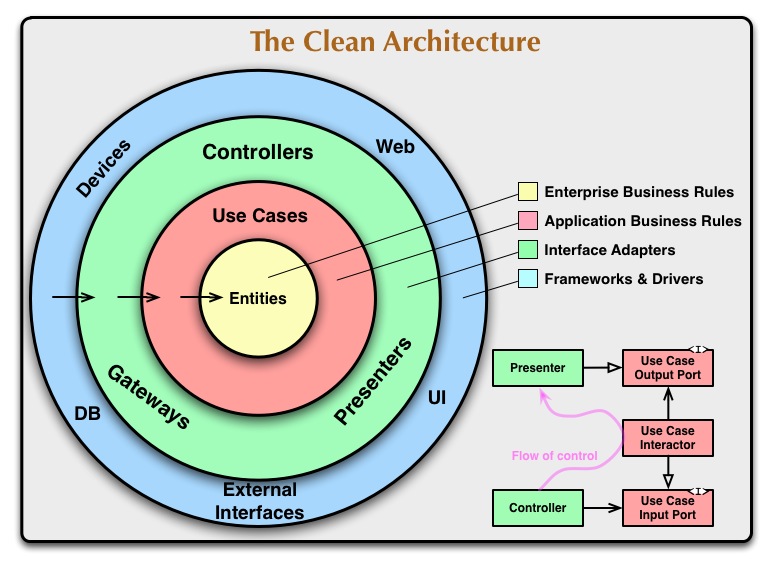
Такое представление кажется чем-то совершенно новым, по сравнению с классической слоёной архитектурой. Но нет, если изобразить обе архитектуры в едином формате:
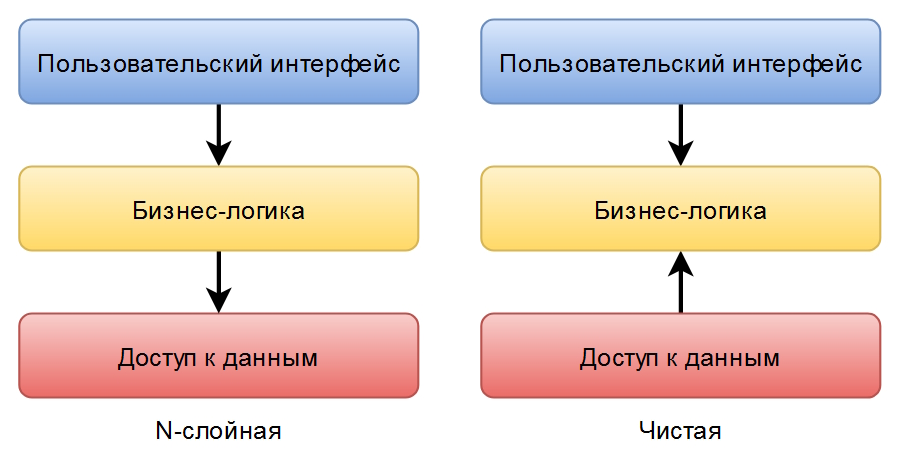
Изменилось лишь направление зависимости между двумя слоями. Это и есть основная идея чистой архитектуры: сделать наиболее важную часть приложения — бизнес-логику независимой от деталей хранения данных в энергонезависимой памяти. Представленная выше интерпретация схемы зависимостей тоже не новость — аналогичные варианты можно встретить статье Layers, Onions, Ports, Adapters: it’s all the same опубликованной Mark’ом Seemann в конце 2013-го года (перевод на Хабре).
Смена направления зависимости реализуется конечно же за счёт принципа Инверсии зависимостей (Dependency Inversion) из пятёрки SOLID. Было бы неплохо отразить это в схеме зависимостей добавив абстракции уровня доступа к данным:
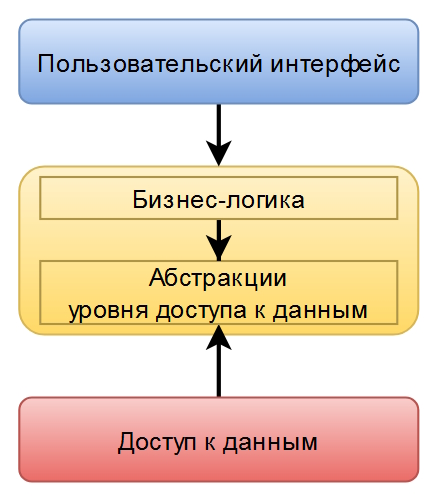
Схема получилась не очень «удобной», потому что и абстракции уровня доступа к данным, и бизнес-логика скорее всего будут находиться в одном модуле. Растащить их по разным модулям можно, но это ничего не даст. Однако суть отражена верно: бизнес-логика и доступ к данным никак не зависят друг от друга, но оба зависят от абстракций.
Предлагаю не останавливаться на достигнутом и добавить в схему ещё деталей. Современный подход разработки ПО предполагает активное использование сторонних библиотек, реализующих общую функциональность. Например реализация уровня доступа к данным наверняка будет с использованием Entity Framework, LinqToDb, NHibernate или Dapper. Ну или других, менее популярных библиотек.
Также часто выделяют модели предметной области в отдельный модуль. Попробуем отразить это на схеме:
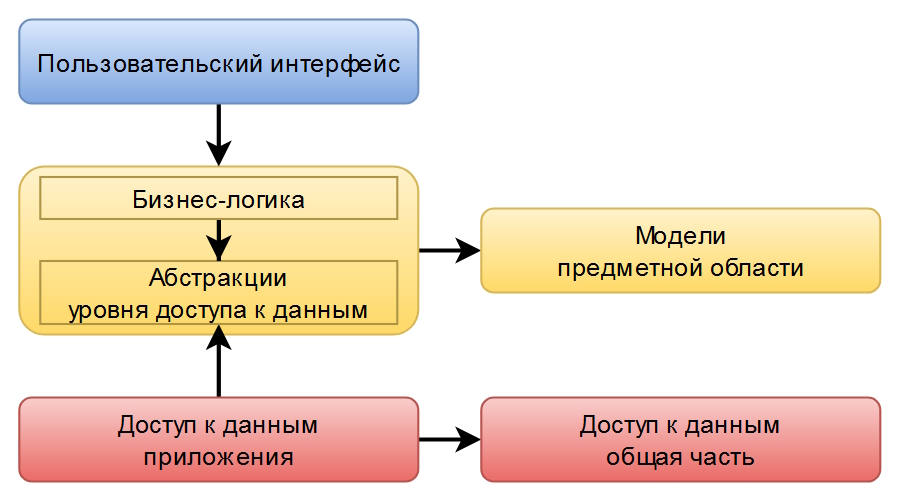
Вам это ничего не напоминает? А если вот так:
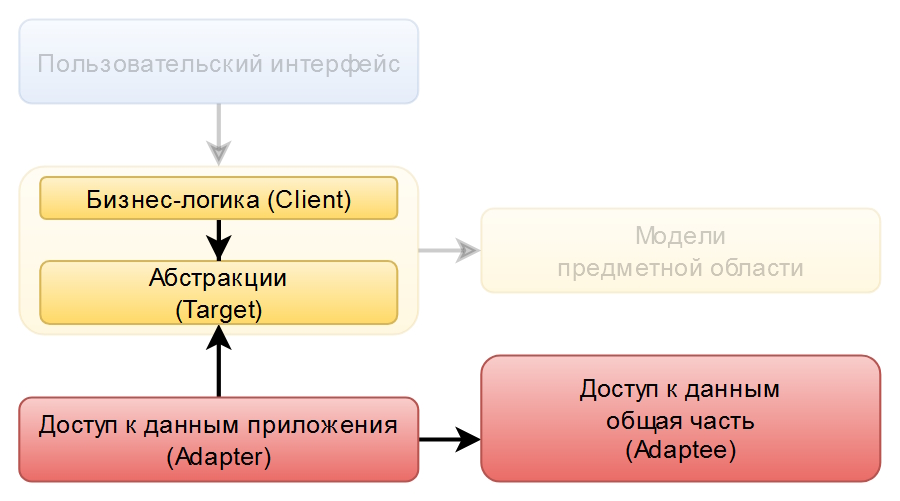
Наблюдается некоторое сходство с UML диаграммой шаблона проектирования Адаптер.
Напомню, что задача Адаптера состоит в преобразовании интерфейса класса недоступного для модификации к интерфейсу подходящему для потребления клиентом.
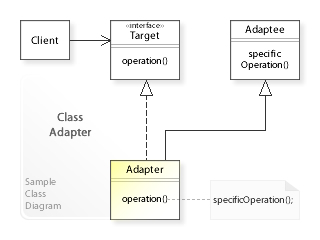
Понимаю, что упоминание шаблона Адаптер в текущем контексте может показаться «притянутым за уши», однако прошу вас не торопиться с выводами, поскольку такая интерпретация поможет выявить проблему и, возможно, найти подходящее решение. Дело в том, что получившаяся схема зависимостей содержит одно любопытное противоречие:
- С одной стороны, чем ближе абстракция к реализации, тем меньше усилий понадобиться разработчику для создания адаптера. Но в этом случае реализация начинает зависеть от конкретной библиотеки (framework’а) доступа к данным. Что в свою очередь нарушает один из постулатов чистой архитектуры, а именно «Независимость от фреймворка».
- С другой стороны, если попытаться абстракцию сделать как можно более универсальной и независимой от конкретного framework’а, то это может привести к значительным трудозатратам при реализации адаптера. Более того: разработка достаточно универсальной и в то же время удобной абстракции — не простая задача.
Разработчики пытаются балансировать между этими двумя крайностями, но так или иначе скатываются к одной из них.
Например: при разработке нового проекта, следуя заветам дядюшки Боба, принимается решение скрыть EF Core за интерфейсом репозитория, абстракция которого имеет следующий вид:
public interface IUserRepository
{
void Insert(User user);
void Update(User user);
void Delete(int id);
User GetById(int id);
User GetByLogin(string login);
IEnumerable<User> GetByNameAndBirthdate(string firstName, string lastName, DateOnly birthdate);
// и т.п.
}Вроде бы достаточно универсально и в реализации не сложно. Правда в процессе использования может возникнуть ощущение некоторого неудобства, потому что для каждой операции получения данных требуется реализовать отдельный метод. Репозиторий растёт как на дрожжах и надо бы с этим что-то делать. В процессе поиска решения может выясниться, что описанная выше реализация это вовсе и не репозиторий, а Data Access Object. А репозиторий это в первую очередь некоторое множество однотипных объектов (коллекция). И чтобы ограничить эту коллекцию применяют шаблон проектирования Спецификация. Следовательно абстракция репозитория должна выглядеть как-то так:
public interface IUserRepository
{
void Insert(User user);
void Update(User user);
void Delete(int id);
IReadOnlyCollection<User> Query(ISpecification<User> specification);
}Это частично решает проблему удобства и дублирования по части ограничения данных, но не решает по другим аспектам, таким как сортировка, постраничный вывод, упорядочивание и т.д. Можно ли с этим что-то сделать? Да — один из соавторов упомянутой выше статьи «Общие архитектуры веб-приложений» Steve Smith, известный также как Ardalis, предлагает свою реализацию спецификации:
public interface ISpecification<T>
{
ISpecificationBuilder<T> Query { get; }
IDictionary<string, object> Items { get; set; }
IEnumerable<WhereExpressionInfo<T>> WhereExpressions { get; }
IEnumerable<OrderExpressionInfo<T>> OrderExpressions { get; }
IEnumerable<IncludeExpressionInfo> IncludeExpressions { get; }
IEnumerable<string> IncludeStrings { get; }
IEnumerable<SearchExpressionInfo<T>> SearchCriterias { get; }
int? Take { get; }
int? Skip { get; }
Func<IEnumerable<T>, IEnumerable<T>>? PostProcessingAction { get; }
bool CacheEnabled { get; }
string? CacheKey { get; }
bool AsTracking { get; }
bool AsNoTracking { get; }
bool AsSplitQuery { get; }
bool AsNoTrackingWithIdentityResolution { get; }
bool IgnoreQueryFilters { get; }
IEnumerable<T> Evaluate(IEnumerable<T> entities);
bool IsSatisfiedBy(T entity);
}Как вы считаете, это «Спецификация» или больше похоже на QueryObject? И нет ли тут привязки к конкретной ORM ? 🙂
Ну да ладно, закроем пока на это глаза, потому что проблемами получения данных мы не ограничимся. С изменением тоже не всё так просто. Точнее сказать: всё просто при работе с единственной сущностью, а вот если логика требует изменить множество сущностей из разных репозиториев, то приходится «поломать голову» как это сделать. Нередко в таких случаях бизнес-логика «переезжает» в репозиторий, вместо того, чтобы использовать шиблон проектирования Единица работы (Unit of Work). Или используются «костыли» в виде TransactionScope или явного управления транзакциями соединения.
И вот сидит разработчик и думает как бы ему обойти ограничения неудачной абстракции или сделать её более удобной, вместо того чтобы заниматься непосредственно реализацией проекта. Знакомо?
Чтобы не попасть в подобную ситуацию единственно правильным решением будет использовать готовое решение, а не пытаться в сжатые сроки реализовать что-то своё с нуля. Благо на просторах интернета таковых решений полно. Да взять, хотя бы ABP Framework, к примеру: там и спецификация, и репозиторий, и единица работы в наличии. Документация опять же, примеры кода… в общем всё в лучшем виде — бери да пользуй.
И всё бы хорошо, но в процессе реализации очередного репозитория может возникнуть вопрос: это осознанный выбор или потому что здесь так принято ? Ну т.е. независимость от фреймворка, и как следствие применение шаблонов проектирования Единица работы, Репозиторий и Спецификация обоснованно решением какой-то технологической проблемы, согласно требований проекта, или же это просто следование общепринятым рекомендациям и опыта предыдущих реализаций? 🙂
Мне этот вопрос постоянно не давал покоя, потому что расплатой за универсализм всегда было и будет наше время, удобство и производительность системы. И вот в какой-то момент я нашёл в себе смелость отказаться следовать принципу «независимость от фрейморка». Идея заключалась в создании абстракций на основе API Entity Framework. Таким образом на бизнесовом уровне была доступна вся мощь и удобство EF Core, но не напрямую, а через абстракции. И в то же время на реализацию этих абстракций требовалось минимум трудозатрат. Это как раз другая крайность описанного выше противоречия.
Однако, нашёлся разработчик, который пошёл ещё дальше. Знакомьтесь Jason Taylor. Jason уже несколько лет предлагает своё видение чистой архитектуры. В его реализации нет ни спецификации, ни абстракции репозитория. Вся работа с уровнем доступа к данным ведётся через абстракцию контекста БД EF Core:
public interface IApplicationDbContext
{
DbSet<TodoList> TodoLists { get; }
DbSet<TodoItem> TodoItems { get; }
Task<int> SaveChangesAsync(CancellationToken cancellationToken);
}Да-да, вам не показалось — DbSet в качестве репозитория, а стало быть уровень бизнес-логики напрямую зависит от пакета Microsoft.EntityFrameworkCore. Это значит, что схема зависимостей изменилась и приняла следующий вид:
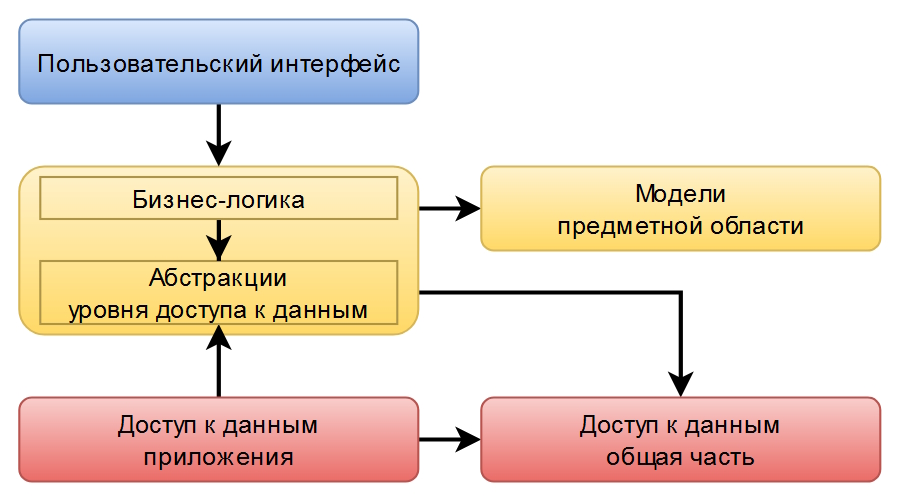
Как вы считаете, это чистая архитектура? А вот так:
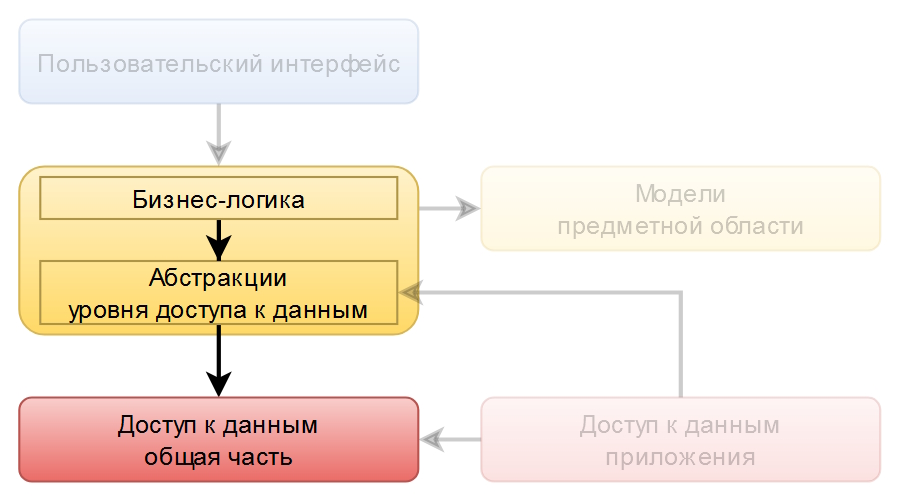
Есть «некоторое сходство» со старой-доброй N-слойной архитектурой, не так ли? Инверсия зависимости уровня доступа к данным приложения ситуацию не меняет. Подтверждают это присущие N-слойной архитектуре недостатки:
- Зависимость бизнес-логики от уровня доступа к данным. И от этой зависимости невозможно избавиться, т.е. удалили ссылку на EF Core из модуля Application и вся логика посыпалась, как карточный домик.
- Невозможность тестировать бизнес-логику модульными тестами. Доступны только интеграционные (7.0, 8.0), из-за жёсткой привязки к ORM, а через неё и к СУБД.
Что же касается плюсов, то в первую очередь это простота (если б ещё не MediatR…). В своём решении Jason организует бизнес-логику в виде сценариев использования (use-case scenario). Такая реализация особенно хорошо подходит как раз для веб-приложений. Но только теперь, как уже упоминалось выше, на этом уровне становится доступна вся мощь LINQ и методов расширителей специфических для EF Core. А это прекрасно задокументированный и хорошо всем знакомый API. Стало быть с задачей манипулирования данными не должно возникать проблем даже у начинающего разработчика. Впрочем возможности не ограничиваются только EF Core. Есть замечательный проект linq2db.EntityFrameworkCore, который предоставляет интеграцию EF Core с Linq2Db. А это значит становятся доступными:
- Расширенный синтаксис объедиения данных (Joins).
- Обобщенные табличные выражения (Common Table Expression).
- Массовый импорт данных (Bulk Copy).
- Оконные функции SQL (Window Functions).
- Операции слияния данных (Merge).
- Временные таблицы, Insert From Select, хинты, SQL-функции и кое-что ещё по мелочи.
Неплохо, а?
С таким функционалом любые манипуляции с данными — не проблема.
К тому же при желании ничего не мешает использовать шаблон проектирования спецификация в виде методов-расширителей IQueryable, или в виде стороннего решения использующего деревья выражений.
Расширить функционал репозитория тоже не проблема — опять таки методы-расширители в помощь. Например в решении Jason’а имеется класс PaginatedList<T>, представляющий собой коллекцию для постраничного вывода элементов. Статический метод CreateAsync можно было бы сразу реализовать в виде метода-расширителя IQueryable<T> следующим образом:
public static async Task<PaginatedList<T>> ToPaginatedListAsync<T>(this IQueryable<T> source, int pageNumber, int pageSize, CancellationToken cancellationToken = default)
where T : class
{
var count = await source.CountAsync(cancellationToken);
var items = await source.Skip((pageNumber - 1) * pageSize).Take(pageSize).AsNoTracking().ToListAsync(cancellationToken);
return new PaginatedList<T>(items, count, pageNumber, pageSize);
}Хотелось бы его ещё затолкать на уровень доступа к данным, где ему самое место, но не получиться. Во всяком случае не в решении Jason’а. Но это вполне реально если не инвертировать зависимость бизнес-логики от уровня доступа к данным приложения, а PaginatedList вместе с абстракциями либо утащить в модуль Domain, либо создать отдельный модуль Application.Abstractions, на который будут ссылаться и Application и Infrastructure.
Теперь что касается тестов — тут прям по классике: «Твой позорный недуг мы в подвиг определим» (с). Т.е. раз уж нет возможности протестировать сценарии использования модульными тестами, то будем тестировать функциональными. Впрочем, есть подозрение, что даже при наличии возможности создания бизнесовых модульных тестов, их всё равно бы не было, при такой-то реализации:
public async Task<int> Handle(CreateTodoListCommand request, CancellationToken cancellationToken)
{
var entity = new TodoList();
entity.Title = request.Title;
_context.TodoLists.Add(entity);
await _context.SaveChangesAsync(cancellationToken);
return entity.Id;
}Хорошо — на этом, пожалуй, закончим краткий обзор решения от Jason’а и перейдём к нашей любимой рубрике «велосипедостроение».
Ранее я упоминал, что пытался спрятать EF Core за абстракциями. Сделать это не сложнее, чем спрятать любую другую статику, типа DateTime.Now, за интерфейсом. Но с разделением API по функциональным обязанностям:
- IQueryable<T> — это QueryObject. Оставляем как есть.
- DbSet<T> — абстракция репозитория в EF Core. Реализует IQueryable<T>, тем самым предоставляя возможность начать построение запроса.
DbSet хоть и абстрактный класс, но находится в пакете EntityFrameworkCore, поэтому необходимо закрыть абстракцией IRepository<T>, в которой объявлены все, или большая часть методов DbSet’а. - Select, Where и прочие методы Linq возвращающие IQueryable — это построитель запроса (Query Builder). Или иначе — шаблон проектирования «Построитель» (Builder) для объекта QueryObject.
Оставляем как есть. - Include, AsNoTracking и прочие методы методы возвращающие IQueryable — это тоже построитель, но поскольку методы находятся в пакете EntityFrameworkCore, их необходимо спрятать за интерфейсом IQueryBuilder.
- FirstAsync, CountAsync и прочие методы выполняющие запрос из пакета EntityFrameworkCore — прячем за интерфейсом IQueryExecutor.
Помимо вышеописанного был создан интерфейс IDbContextTransaction для явного управления транзакциями:
public interface IDbContextTransaction : IDisposable, IAsyncDisposable
{
Task CommitAsync(CancellationToken cancellationToken = default);
Task RollbackAsync(CancellationToken cancellationToken = default);
}И абстракция обёртки контекста БД, являющуюся по совместительству корнем композиции всего, что касается взаимодействия с БД:
public interface IDbContext
{
Task<IAsyncDisposable> OpenConnectionAsync(CancellationToken cancellationToken = default);
Task<IDbContextTransaction> BeginTransactionAsync(CancellationToken cancellationToken = default);
Task<int> SaveChangesAsync(CancellationToken cancellationToken = default);
IQueryExecutor Executor { get; }
IQueryBuilder Builder { get; }
}Напоследок осталось добавить немного синтаксического сахара в виде методов расширителей IQueriable<T> для IQueryBuilder и IQueryExecutor. Да-да: сначала методы-расширители EF Core спрятали за интерфейсом, а затем на его основе создаём методы расширители — такой вот «финт ушами»:
public interface IQueryExecutor
{
Task<TEntity> FirstAsync<TEntity>(IQueryable<TEntity> query, CancellationToken cancellationToken = default);
Task<List<TEntity>> ToListAsync<TEntity>(IQueryable<TEntity> query, CancellationToken cancellationToken = default);
Task<bool> AllAsync<TSource>(IQueryable<TSource> query, Expression<Func<TSource, bool>> predicate, CancellationToken cancellationToken = default);
}
public static partial class QueryableExtension
{
public static Task<TEntity> FirstAsync<TEntity>(this IQueryable<TEntity> query, IQueryExecutor executor, CancellationToken cancellationToken = default)
=> executor.FirstAsync(query, cancellationToken);
public static Task<List<TEntity>> ToListAsync<TEntity>(this IQueryable<TEntity> query, IQueryExecutor executor, CancellationToken cancellationToken = default)
=> executor.ToListAsync(query, cancellationToken);
public static Task<bool> AllAsync<TSource>(this IQueryable<TSource> query, Expression<Func<TSource, bool>> predicate, IQueryExecutor executor,
CancellationToken cancellationToken = default)
=> executor.AllAsync(query, predicate, cancellationToken);
}В качестве тренировочного решения взял проект Jason’а для 7-го .net core.
Вот так операция проверки команды обновления списка элементов была реализована изначально:
public async Task<bool> BeUniqueTitle(UpdateTodoListCommand model, string title, CancellationToken cancellationToken)
{
return await _context.TodoLists
.Where(l => l.Id != model.Id)
.AllAsync(l => l.Title != title, cancellationToken);
}И вот такой она стала после удаления ссылки на EF Core:
public async Task<bool> BeUniqueTitle(UpdateTodoListCommand model, string title, CancellationToken cancellationToken)
{
return await _context.TodoLists
.Where(l => l.Id != model.Id)
.AllAsync(l => l.Title != title, _context.Executor, cancellationToken);
}Желающие могут взять исходники.
Получилось вроде хорошо. И модуль с бизнес-логикой больше не связан с EF Core. Однако есть сомнения в целесообразности данного — какой с этого толк, если модульные тесты использоваться не будут? Быть может со временем возникнут ситуации, где такая абстракция пригодиться… Ладно, пусть будет, оставлю, как говориться, про запас.
И вот ещё что: можно было бы поспекулировать на тему создания некоторого более универсального чем EF Core API интерфейса и заявить, что это уже какая-никакая независимость от фрейморка с инверсией зависимости и т.д. и т.п. Но нет. Потому что суть идеи описываемой в этой статье заключается как раз в отказе от универсализма, если такового не требуется для реализации проекта. Чтобы в итоге получить сокращение издержек на разработку и сопровождение + внятный и хорошо всем знакомый API.