Не так давно я сравнивал Entity Framework Migrations и FluentMigrator и пришёл к выводу, что при использовании Entity Framework для миграции БД лучше подходят его же миграции. Решил на этом не останавливаться и продолжить изыскания дальше. Давайте представим, что мне необходимо написать небольшое приложение для персональных тренировок. Данные хранить предполагается в реляционной базе данных — пусть будет MySQL, раз уж эта СУБД уже развёрнута на моём домашнем сервере. Для наглядного представления сущностей и отношений между ними хорошо бы создать диаграмму «сущность-связь» (ERD). Для этого можно выбрать любое приложение из множества, но стоит учесть, что MySQL Workbench тоже умеет рисовать ER-диграммы. Более того: через контекстное меню можно получить SQL для создания любой сущности диаграммы. Отмечу также, что Workbench в этом не уникален — подобный функционал есть и в других инструментах управления базами данных.
Следующий шаг создание классов моделей и контекста БД:
- при подходе Code first придётся писать код как самих классов, так и контекста БД с нуля, в котором помимо всего прочего придётся также прописывать дополнительную информацию для миграций Entity Framework. И информации этой будет довольно много, если вы хотите тонко настроить свою БД. Усложняет весь процесс то, что на основе моделей и контекста БД будет формироваться промежуточный скрипт миграций, на основе которого будет формироваться и выполняться SQL код во время непосредственного выполнения миграции. Это вызывает некоторое беспокойство: при обновлении рабочей БД более надёжным кажется подход, когда видно какой именно SQL код будет выполнен, нежели иметь некий промежуточный вариант, который уже во время выполнения будет транслирован в SQL. Во всяком случае DBA этому точно не обрадуется.
На всякий случай отмечу, что есть опцияscriptдля командыdotnet ef migrations. - при подходе Database first единственная команда dotnet ef dbcontext scaffold (параметры) создаст все модели и контекст — нужно лишь чтобы БД была в наличии. Откуда же взяться БД — абзацем выше было упомянуто, что некоторые инструменты создания ER-диаграмм позволяют получить SQL-код для создания сущностей. Копируем полученный SQL в скрипты проекта DbUp и получаем систему миграции базы данных на чистом SQL.
Из описанного выше видно, что подход Database first гораздо менее трудозатратен, при условии использования подходящих инструментов на каждом этапе. Но не будем останавливаться только на этом — рассмотрим плюсы и минусы с точки зрения архитектуры:
- Code first позволяет определить модели предметной области в отдельной библиотеке и использовать их же в проекте доступа к данным, доопределив недостающее в контексте БД. При этом получаем либо тощую модель, либо бизнес-логику в DAL’е.
- Database first создаёт собственные DTO использование которых невозможно на уровне бизнес-логики, если придерживаться «чистой архитектуры». Т.е. будет промежуточный слой адаптеров чтобы «подружить» бизнес-логику и уровень доступа к данным в котором будет копирование данных между DTO и моделями предметной области. Но это не то чтобы проблема — как раз для этого были придуманы Mapster, AutoMapper и многие другие. К тому же это позволит разделить уровень бизнес-логики и уровень доступа к данным друг от друга и сделать их полностью независимыми. Что как бы очень даже не плохо и помимо прочего позволяет использовать единственный DAL в нескольких приложениях.
Подытожим: подход Database first кажется менее трудозатратным и более внятным, нежели Code first.
Напоследок несколько диаграмм зависимостей, для размышления:
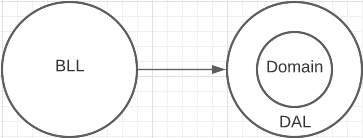
Бизнес-логика зависит от уровня доступа к данным.
подходит для Databse first, если логика ничтожна
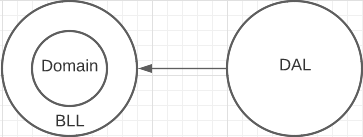
бизнес-логика и предметная область независимы,
но уровень доступа к данным зависит от них.
подходит для Code first
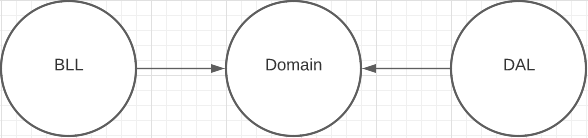
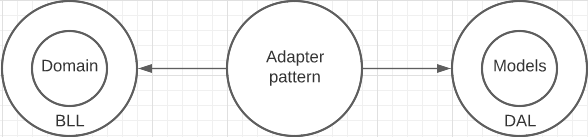
связывание двух слоёв выполнятся через дополнительный слой с типовым решением Adapter
данные между слоями передаются копированием.